
Finding a Feedback Loop
Notes from shipping my first production agentic feature at Pair Team.


Sitting down at my desk, hands on keyboard, an old engineering mantra from my days deep in the SF Bitcoin community reverberated through my mind:
“Don’t trust. Verify”
On the surface this felt like the antithesis of today’s vibe-based engineering culture. Yet, beyond the boisterous rhetoric is a set of practices quickly becoming industry standard for operating non-deterministic systems reliably at scale. Tasked with shipping my first agentic feature, I had a chance to learn what one of those practices actually looks like.
This is my experience.
A Simple Enrollment Call
As an entryway into various programs we offer here at Pair Team, our AI healthcare advocate Flora will conduct an outbound enrollment call. This call is simple. Within the funnel of our service, it sits near the top, operating as a mildly stateful conduit responsible for introducing a patient into our system.
Unsurprisingly, there are roughly four ways this call can go:
No answer
Voicemail
Patient answers and requests a callback
Patient answers and engages
When patients request a callback, Flora’s job is to verbally confirm we’d reach back out to them at an agreed-upon time.. So, in my second week here at Pair Team, I took on the task of helping Flora do this well.
Prompts All the Way Down?
Given some callback time as an output from the call, it was pretty straightforward to then kick off another scheduled call at some future time via our background job processor, Resque. This bit was fairly trivial.
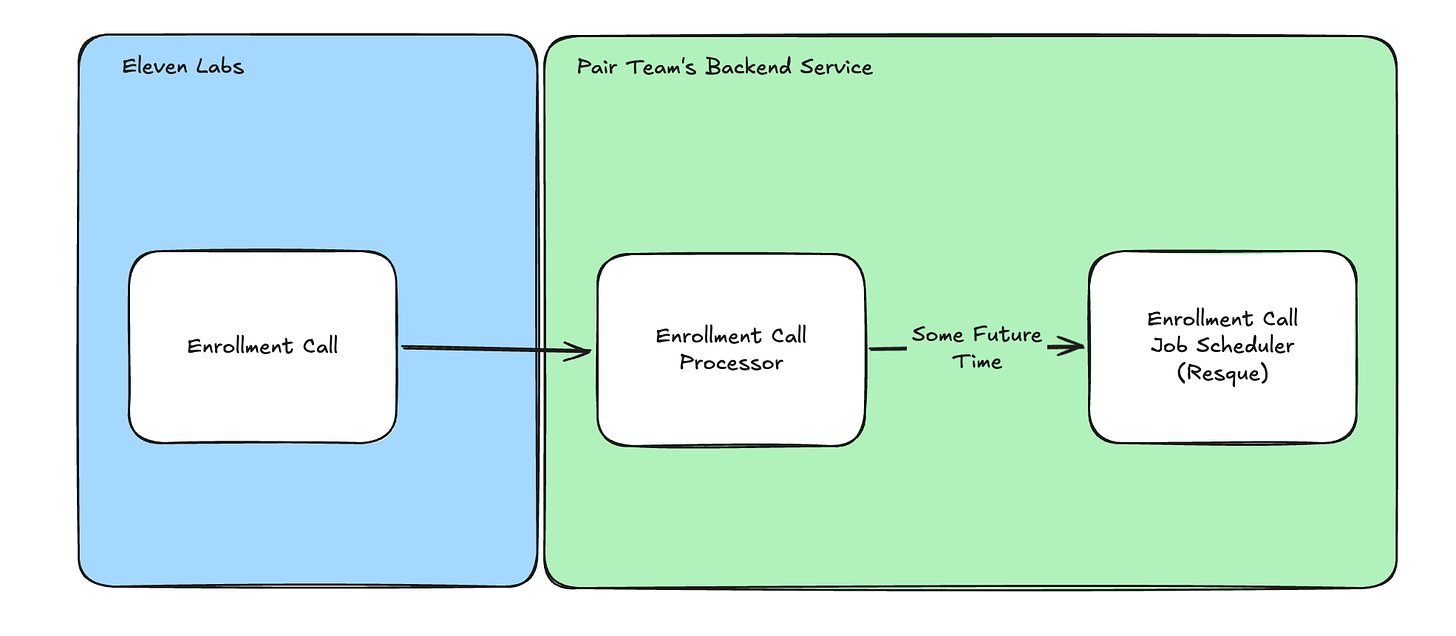
The more interesting part was how do we know when to schedule the callback for? With our partner ElevenLabs, there is a call analysis data collection feature:
Data collection automatically extracts structured information from conversation transcripts using LLM-powered analysis. This enables you to capture valuable data points without manual processing, improving operational efficiency and data accuracy.
And so we can expand upon our design above to extract the callback time on the ElevenLabs side.
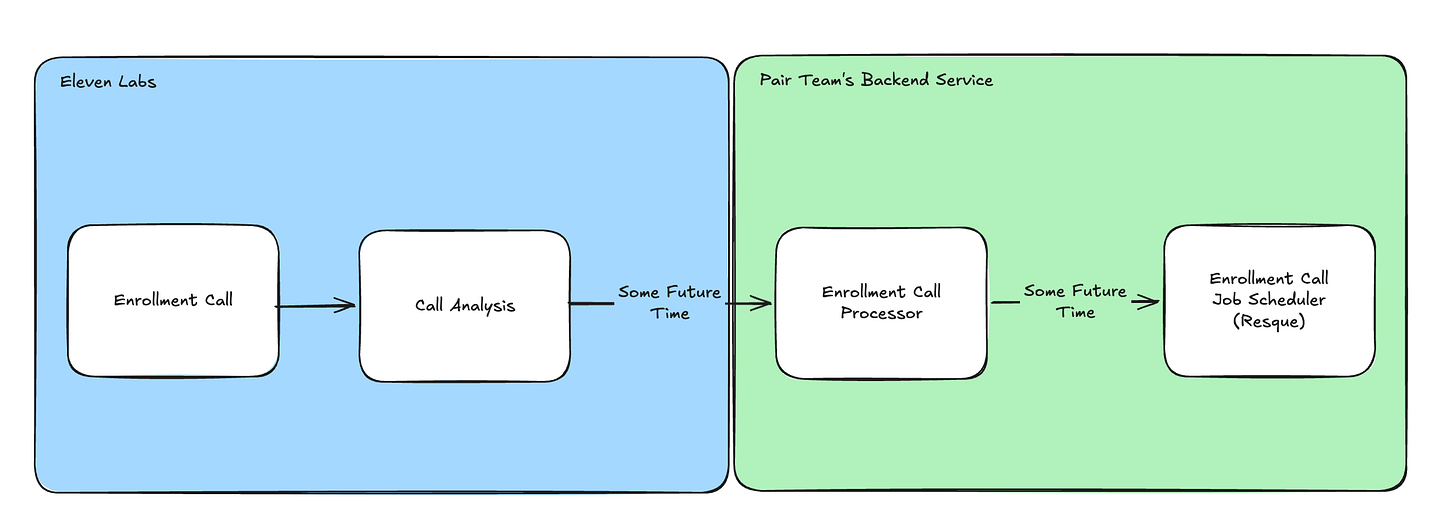
How this actually works is you navigate to the Analysis view in ElevenLabs and create a new Data Collection data point, which comprises: an identifier, a data type, and a prompt.
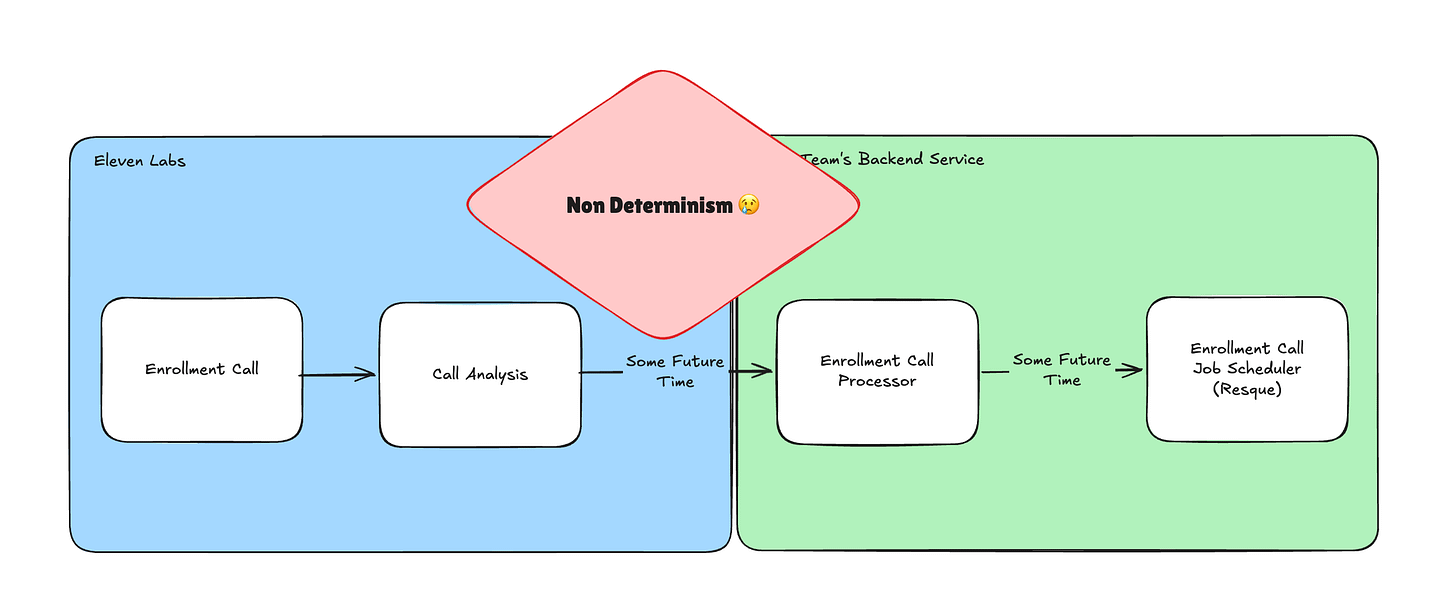
Now on that last point, yes, to extract the requested callback time we do introduce another prompt! Coming from a traditional software background, this made me a bit uneasy. The conversation upstream was already non-deterministic but until now nothing downstream depended on a structured reading of it. The extraction prompt here is the bridge: it takes a non-deterministic conversation and hands a deterministic scheduler something to act upon. That bridge is now wholly dependent on a prompt’s interpretation of the transcript.
Many years ago I made the mistake choice of taking a course in college called Real Analysis. This infamously challenging theoretical math course more or less defeated me, yet the core ideas, at least in principle, stay with me to this day. On the first day of class the professor made a bold claim:
Here are the foundations on which this domain of math is based. If you disagree with its foundations, nothing I will teach you here in the next four months holds.
In any chain of reasoning, if the first link is wrong, what follows can’t be trusted either.
I believe we can leverage that core principle here:
If the extraction isn’t correct, our processing and subsequent rescheduling may also be incorrect.
So, how do we keep this part of the system honest? While this may seem like a low blast radius failure, it is not. For Pair Team, a missed callback is potentially somebody who needed care and didn’t get it.
Developing a Feedback Signal
At first I considered a regex check on the transcript. It seemed that it might be possible to just deterministically search for some datetime and “call back”. However, the core question “did the patient actually request a callback?” is semantic, not syntactic. The set of all possible ways to make this request is likely too large to codify.
And so falling back, what else could we do? It turns out we can just introduce another prompt to keep our load-bearing prompt in check. While a bit tongue in cheek, I am serious. For this we will be employing an LLM-as-Judge eval (see a nice post by Anthropic on evals).
As defined by Langfuse’s docs:
LLM-as-a-Judge is an evaluation methodology where an LLM is used to assess the quality of outputs produced by another LLM application. Instead of relying solely on human reviewers or simple heuristic metrics, you prompt a capable model (the “judge”) to score and reason about application outputs against defined criteria.
Given what context we have, our evaluation process will then look a bit like this with an implicit model operating as part of the eval diamond and the prompt here being the eval prompt. This runs asynchronously post-call, after the enrollment call processor stage in the diagram above, so the eval adds no latency to the patient experience.
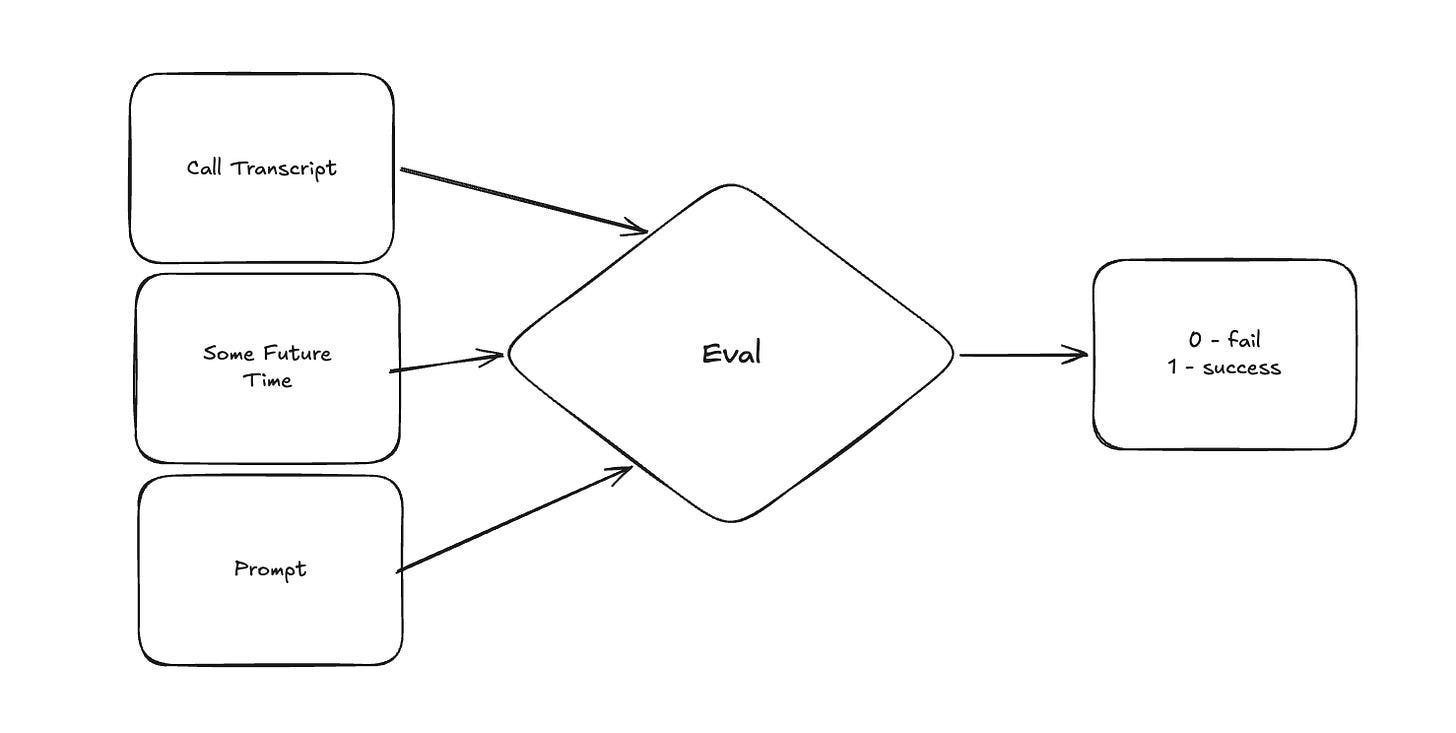
Now the astute reader will likely interject: we’re solving a prompt problem with another prompt?
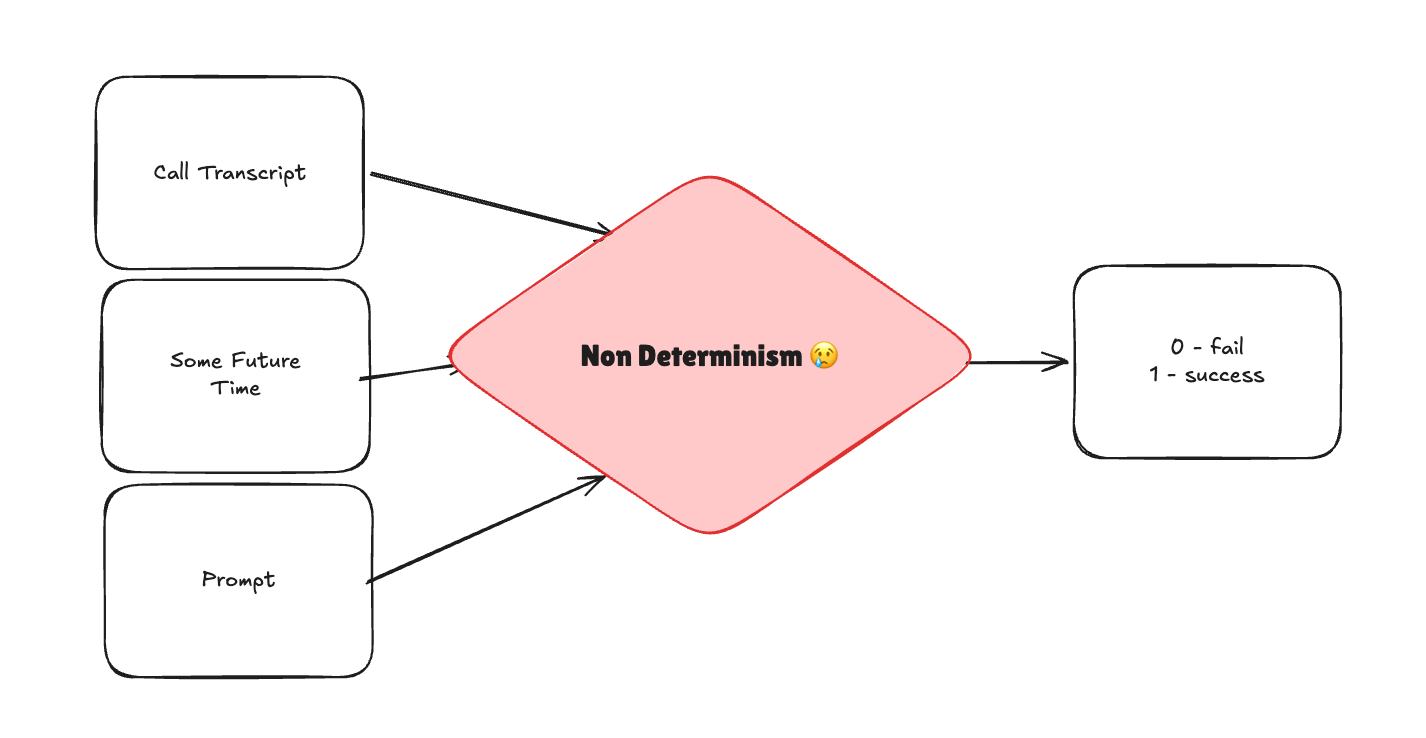
And yes, you are not wrong! Again, coming from traditional software and an SRE background, that was my reaction as well. Yet, done right, this eval method is highly effective. While there are known LLM-as-Judge failure modes (position bias, verbosity bias, calibration drift) and an art and science to writing good evals more broadly (out of scope of this post, stay tuned for further posts where we will dive deep into these topics), by introducing even a basic judge here as a foundation we can iterate upon, we now have a mechanism to get feedback on the foundation of our simple feature here.
As an example iteration, after some reading and chatting with the team, I ensured that our eval was using a different model (OpenAI GPT-5) than the extraction prompt (Google Gemini 3.5 Flash) to mitigate the potential for bias (some relevant papers Zheng et al., 2023, Panickssery et al., 2024, Xu et al. 2025,.
Furthermore our prompt incorporated lessons from manual review, so we had confidence we were starting with a decent foundation.
With our online eval now live (online here meaning operating against actual user artifacts), I worked with my team to plumb our eval scores into Datadog. Since we had taken the time to reduce the set of possible outcomes, we ensured the output of the eval was easy to consume as a metric.
To get there, we came up with a rubric.
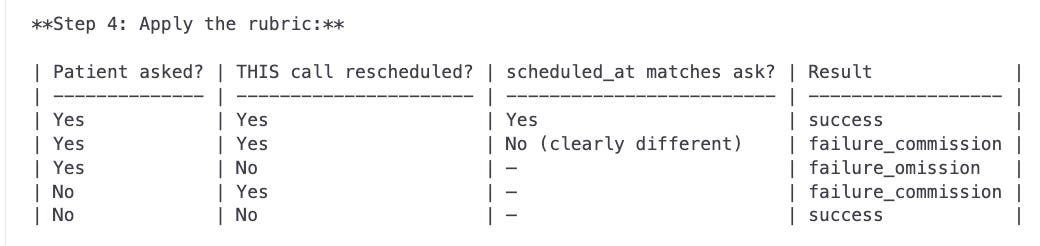
And then we specified how to translate these to numeric values (ignoring irrelevant situations).

With this, we could now monitor in real time how well our extraction prompt is operating without even leaving our Datadog dashboard. My SRE brain was now satisfied.
A Step Beyond
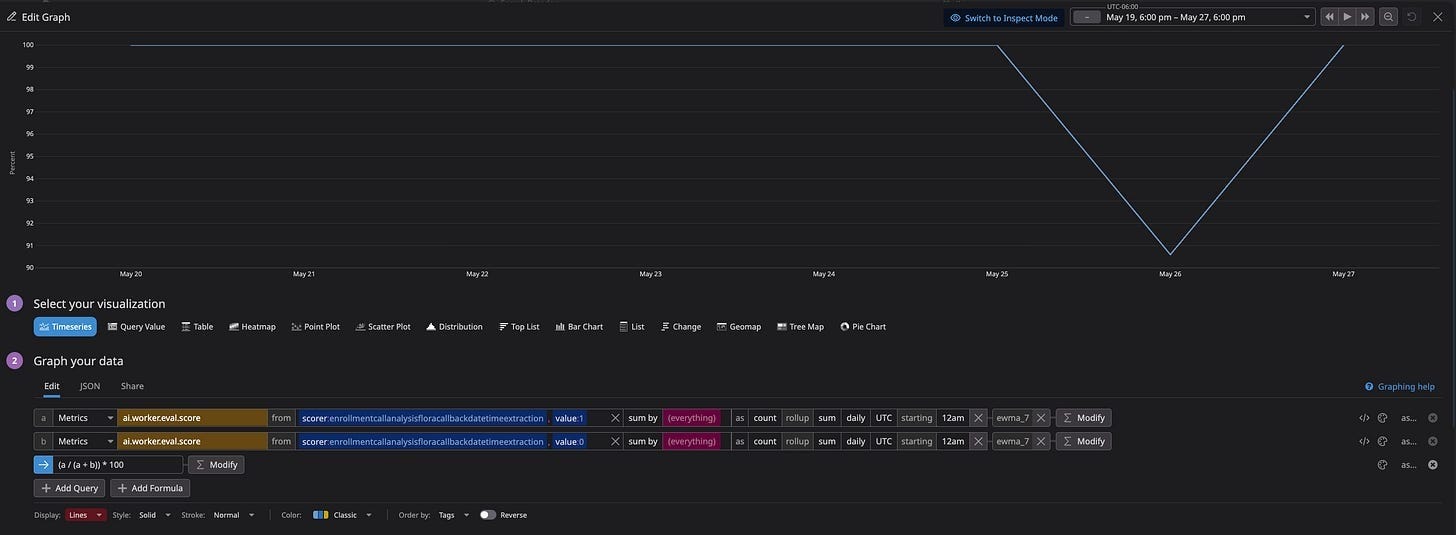
As I continued monitoring this feature in production, I experimented with a couple of different mechanisms to further leverage the signal we’d surfaced via our online eval. For starters, I have had a lot of success leaning on service-level objectives (SLOs) in the past to operate production systems at scale. So, it seemed sensible to take our metric from above and reason about what success here meant. Presumably we’d want to watch for regressions, but on top of that likely assert some minimum success rate % as the bar.
It turns out we’re in the green! Truth be told I would probably love one more nine… However, we now had something useful and easily communicable to present in our weekly Quality of Service meeting to demonstrate whether this specific feature was reliable or not.
We Found Our Feedback Loop
We’ve been running this feature in production for about six weeks now.
The other day our eval surfaced an edge case where the extraction prompt was misreading Flora’s own voicemail line (her “I’ll call you back”) as a patient-requested callback. No extra calls were placed (the failure was internal to our scheduling logic), but as interpreted, Flora was scheduling callbacks to herself. Circling back to the feedback loop we set up, we discovered this post-eval at the human-in-the-loop step while monitoring our SLO on our pod dashboard for the week.
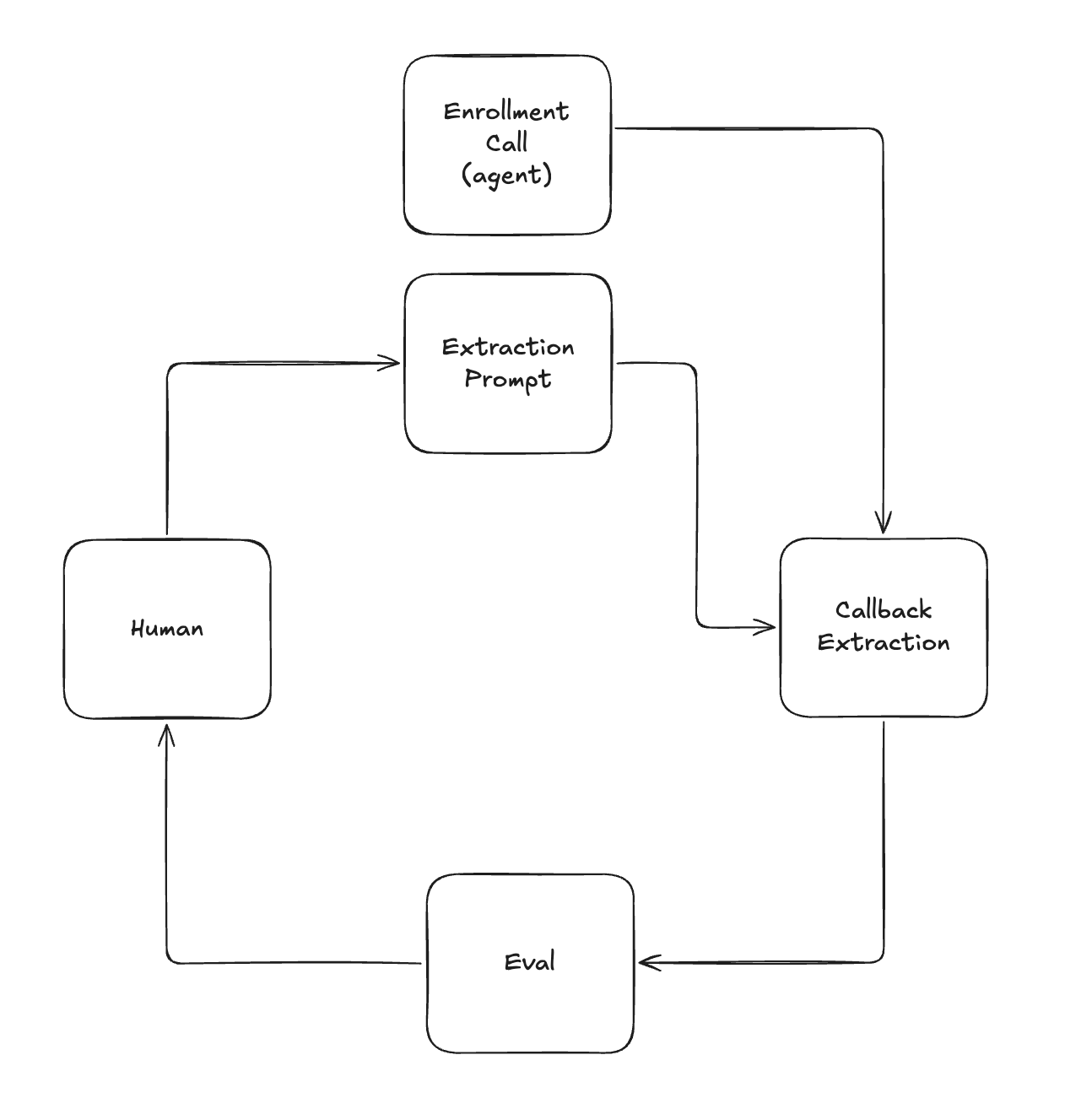
So, we added the offending transcript to an ad hoc offline eval set, iterated on the extraction prompt until it correctly distinguished the two, and shipped a fix. For those curious, we’re actively developing our formalized offline eval approach. As part of this we will include adversarial examples (like the ad hoc one here) in our dataset. More on that coming soon!
Ultimately, turning an unease of working with non-deterministic flows into a quantitative feedback loop has made this work feel less vibes-driven and more empirical. And most importantly this helps me sleep better at night knowing that I’ve contributed to higher quality patient care and spend much less time combing through Langfuse traces by hand.
“Don’t trust, verify”
 | A guest post by
|